A Map of the Territory
This book is a work in progress!
×If you see a mistake, find something unclear, or have a suggestion, please let me know. To follow its progress, please join the mailing list:
(I post about once a month. Don’t worry, I won’t spam you.)
2 . 0程序语言世界的地图
你手中得握着一张地图,不管这张地图有多么简陋。要不然,你会在路途中迷失方向。在《魔戒》这部书里,我不会让任何人走超过他当天所能走过的最远的路。 约翰·罗纳德·瑞尔·托尔金
我们可不想在旅途中迷失方向,所以在正式启程出发之前,让我们好好翻看前辈们为我们绘制的地图,认清我们此行应去往何处,以及前辈们已经开拓出的道路。
首先,让我来简单明确几点。本书大部分内容都是关于一门程序设计语言的具体实现,这与程序设计语言本身是完全不同的。像“栈”、“字节码”、“递归下降”这些听起来唬人的词汇,不过是实现某门程序语言可能会采用的的技术方法。从程序语言使用者的视角来看,只要他们手中的“奇妙装置”(编译器 / 解释器)产出的结果符合程序设计语言定义好的规范即可,并不太关心语言实现的具体细节。
我们将在程序语言实现的具体细节上花上很多时间,如果我每次在提及到它的时候都严格写下“程序设计语言的实现”一词,那我的手指可真受不了(字符实在是太长啦)。所以,除非有严格区分的必要,我会直接使用“语言”一词指代程序语言或是程序语言的实现。
2 . 1程序语言面面观
早在计算机历史的洪荒时代,勤劳聪慧的计算机工程师们就开始着手构建计算机程序设计语言了。因为我们发现,直接与计算机沟通太过困难,计算机只认识二进制机器码,所以得寻求“程序语言”的帮助。现如今的计算机比起洪荒时代,运算速度快了百万倍千万倍,存储空间也有了几个数量级的提升,但构建计算机程序设计语言的方式却几乎没有太大变化,这真是很有趣。
尽管程序语言设计师们探索过的领域如此广阔,但被他们留下足迹证明此路可达的道路却少之又少。虽然不是每一门程序语言都会走完全相同的实现道路(有的语言会省略其中几步,有的还会抄近路)。但令人欣慰的是,从海军准将葛丽丝·霍普女士的第一支 COBOL 编译器到时下大热的编译到 JavaScript 程序语言(它们中某些仅有一份躺在 Git 仓库中的简陋 README 自述文档),都遵循着一脉相承的道路。
我把程序语言的编译过程绘制成了一副路径图,看着就像登山一样。从山脚开始,开发者所写的程序只是一串字符序列构成的纯文本。之后的每一阶段,程序都会被分析、转化为某种更为高阶的表示形式,程序语义(即:程序员想让计算机做的事)也变得越来越明晰。
当我们终于到达到山顶的时候,我们就可以鸟瞰全局,完全理解程序代码想要表达的真正含义。随后,我们从另一侧下山。下山的过程即是把程序的高阶表示形式一步步转化为越来越靠近 CPU 的低阶表示形式,最终到达 CPU 可以执行的机器码。
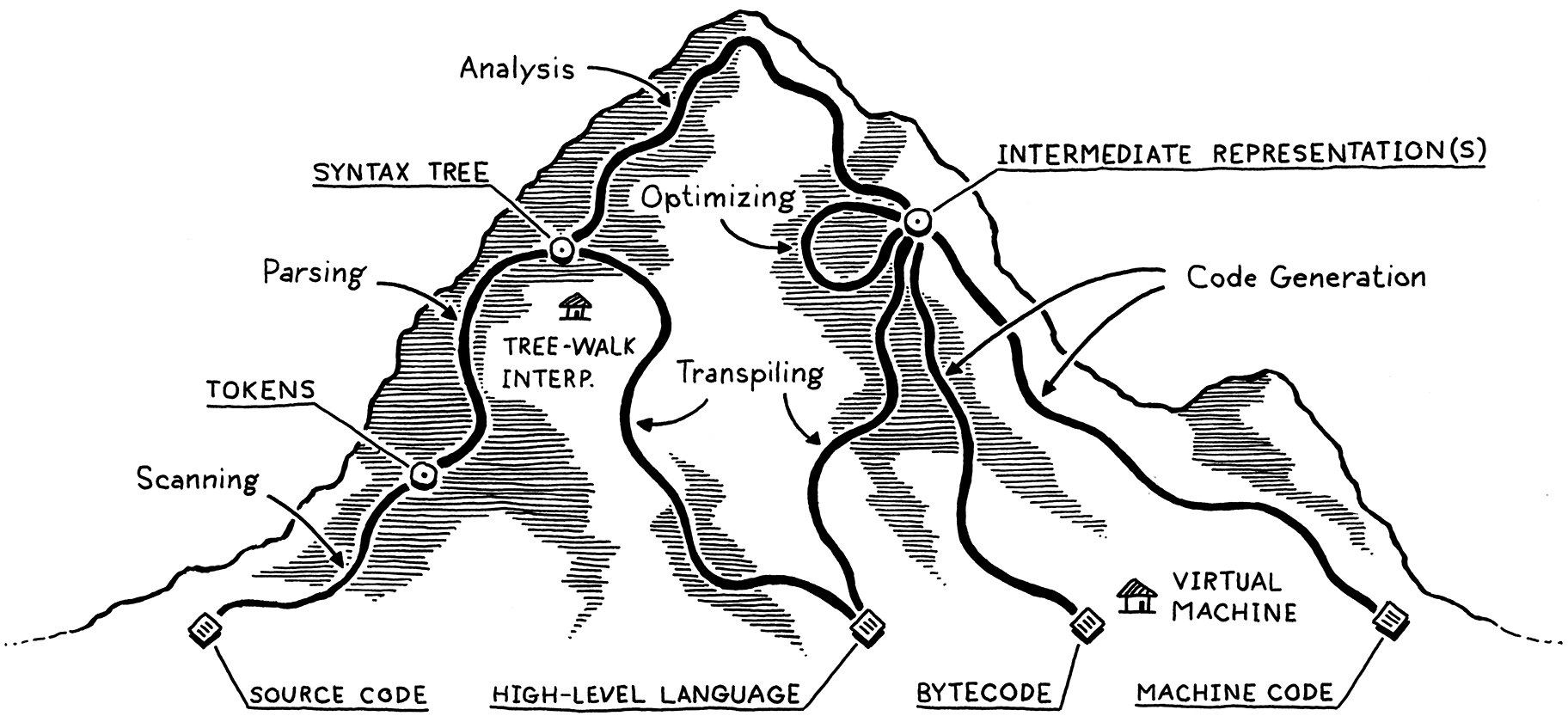
让我们通过一个实例来追踪程序编译的整个过程,看一看在每个编译阶段都会发生哪些有趣的事情。我们从下面这行用户程序源代码开始:

2 . 1 . 1词法扫描(Scanning)
万里长征的第一步是词法扫描(Scanning),也叫做词法化(Lexing),或词法分析(Lexical Analysis)。它们都表示同一个意思,如果你想让旁人印象深刻,可以用听上去最为惊艳的“词法分析”。我个人比较喜欢“词法化”,这听上去就像是某个超级大恶魔会才会做的事情。但在这里,我还是使用“词法扫描”,因为“扫描(Scanning)”一词看起来更为平易近人。
词法扫描器(Scanner),或者说分词器(Lexer),读取一连串程序源代码字符流,按照一定的规则将代码字符分割为一系列的“词”。在程序设计语言领域,我们把这些“词”称之为词法单元(Token)。有些词法单元仅有单个字符,如:左小括号(、逗号,。有些词法单元则由多个字符组成,如:数字123、字符串字面量"hi!"、标识符min。
程序源代码中的某些字符通常不表达任何含义,比如:空白字符、注释。词法扫描器通常简单地忽略它们,仅保留那些有意义的词法单元。
![[var] [average] [=] [(] [min] [+] [max] [)] [/] [2] [;]](image/a-map-of-the-territory/tokens.png)
2 . 1 . 2语法分析(Parsing)
接下来的一步叫做语法分析(Parsing)。通过分析程序的词法从而得到语法(Grammar),将相互关联的几个词法单元拼装组合变成更加复杂的表达式和语句的能力。还记得小时候上文法课的情景吗,标注一句话的语法成分(主、谓、宾、定、状、补),你那时做的事便是“语法分析”。只是,英语这门语言包含着成千上万的“关键字(Keywords)”,以及大量意思相近的歧义词。程序语言则简单许多。
语法解析器(Parser) 读入 token 词法单元序列,构建出符合当前代码语义的树型结构,因为语法是嵌套的,所以要用树来表示。这些树型结构有着很多不同的名字:解析树(Parse Tree)、抽象语法树(Abstract Syntax Tree),具体叫什么取决于这棵树与程序语言语法结构之间的对应程度。在实践中,程序语言开发者们习惯称呼它们为语法树(Syntax Tree) 或 抽象语法树(AST),也有人为了简单起见直接叫树(Tree)。
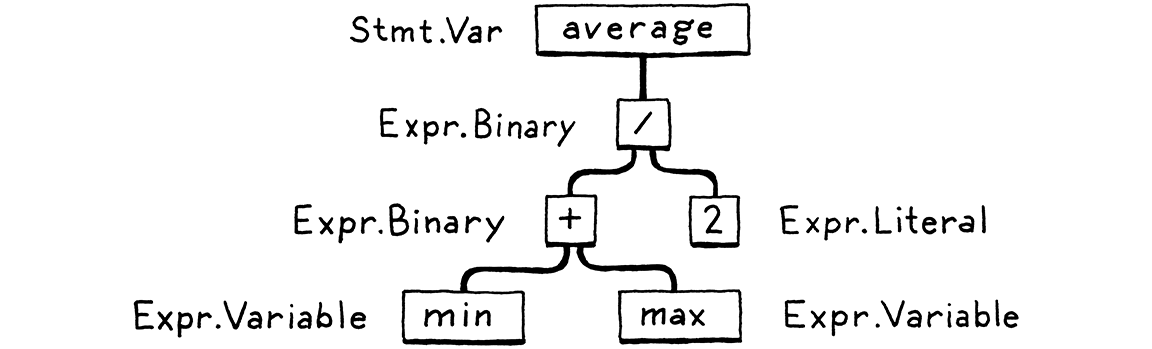
在计算机科学领域,语法解析技术有着漫长且丰富的历史。语法解析还与人工智能有着千丝万缕的联系。现如今程序语言所用的很多语法解析技术,最初都是 AI 研究者们为解析人类语言而发明的。他们想让计算机与我们交流对话。
后来,研究者们发现,人类所使用的语言实在太过复杂,仅能处理严谨语法的语法解析器处理不了如此复杂的人类语言。但是语法解析器非常适合用来处理语法严谨、毫无歧义的程序语言,毕竟,程序语言可比人类语言简单多了。但即使是使用语法如此简单的程序语言,我们程序员还是会在写代码时犯各式各样的语法错误。所以语法解析器的职责又多了一条:报告程序员们所犯的语法错误,让他们改正。
2 . 1 . 3静态分析(Static analysis)
几乎所有的程序设计语言实现都会经历词法分析、语法分析这两个阶段。那么在此之后,不同的程序语言就要开始展现其各自实现特点了。在当下这个节点,我们仅知道程序代码的语法结构,如:表达式之间的嵌套关系等。除此之外就没有更多的信息了。
如有表达式a + b,我们知道需要对a和b执行加法运算,但是我们不知道a和b这两个名字到底指向哪里,指向本地变量还是全局变量?变量定义在何处?
对于大多数程序语言而言,分析语法树的第一步叫做 标识符绑定(Binding) 或 标识符解析(Resolution) :对于语法树中的每个标识符,找到这枚标识符被定义的地方,把它和语法树中标识符所在的位置关联起来。这个时候 作用域(Scope) 就开始发挥作用了:作用域规定了一枚既定标识符在源代码中所能被正确解析的区域。
如果这是一门静态类型的程序语言,此时也是我们做类型检查的时候。一旦我们找到了a和b在何处声明,我们就可以很容易地确定它们的类型。如果a、b类型之间无法相加,那么我们就可以抛出一个类型错误。
做个深呼吸,我们已经抵达了山顶,对用户程序也有了一个全面的认知。从静态语义分析中得到的讯息都需要被妥善存储起来。有一些地方可供我们存放这些讯息:
- 通常,我们可以把这些讯息作为语法树节点的 属性(Attributes) 存储起来。为树节点添加一些额外属性字段,在构建语法树时将字段留空,后续再将静态语义分析得到的信息填充进去。
- 另外,我们还可以将这些数据存储到一张查找表里,以标识符(变量名、函数名、变量声明、函数声明等等)作键,标识符语义信息为值。如此一来,我们就可以轻松找到某个标识符的引用信息了。我们把这张表称为:符号表(Symbol table)。
- 最为强大的信息记录工具就是将语法树转化为一种全新的数据结构,这种数据结构可以更为直接地表达代码的语义信息。下一节就将介绍这部分的内容。
到目前为止,我们所讲的词法分析、语法分析、语义分析三阶段,通常被归类为编译 “前端(Front end)” 。你也许会想,那之后的流程都是编译 “后端(Back end)” 了,可惜不是。在过去那个只有“前端”和“后端”的年代,编译器比现在简单许多。后来,程序语言研究者们在“前端”和“后端”之间插入了几个新阶段。威廉·伍尔夫教授和一众大企业将这些新阶段汇总打包,遵照古老的命名习惯,起了个魅力十足但又稍显矛盾的名字:“中端(Middle end)” 。
2 . 1 . 4中间代码表示(Intermediate representations)
你可以把编译器想象为一条流水线,流水线的每一道工序都将用户代码加工成某种特殊的数据表示形式,方便下一道工序使用。编译流水线“前端”主要关注程序的源代码结构(词法、语法、语义),“后端”则主要关注程序最终执行平台的体系架构。
在编译“中端”,程序代码可能会被存储为某种中间代码(Intermediate representations、IR)形式,既不贴近源代码也不贴近机器码,处于两者之间(所以称为“中间代码表示”)。IR 中间代码更像是介于源代码与二进制机器码之间的接口。
有了 IR 中间代码的帮助,在支持多程序源码解析与多目标平台编译方面,就可以省下很多力气。比如说,你想要实现 Pascal,C,Fortran 这三门程序语言的编译器,期望程序编译到的目标平台为 x86,ARM,SPARC。通常情况下,这意味着你得编写9支完整的编译器:Pascal→x86,C→ARM,以及其他排列组合。
通过借助一个共享的 IR 中间代码表示,我们的工作量将大大减少。只需要为每一门程序语言编写一个“前端”,将程序源代码编译为中间代码表示,再为每一个目标平台编写一个“后端”,将中间代码编译到目标平台的二进制机器码。之后,我们的任务就完成了,所有排列组合都覆盖得到。
另一个促使我们将代码转化为 IR 中间代码表示的重要原因是:使用 IR 中间代码可以使程序语义变得更加清晰 . . .
2 . 1 . 5代码优化(Optimization)
当我们完全理解用户程序想要表达的含义之后,我们就可以放心地将用户源程序替换为一支语义完全相同、运行效率更高的新程序。也就是说,我们可以优化程序代码。
一个简单的例子就是常量折叠(Constant Folding):如果某些表达式求值始终为常量,我们便可以在编译时用常数值替换整个表达式。如以下用户代码:
pennyArea = 3.14159 * (0.75 / 2) * (0.75 / 2);
我们可以在编译时完成整个表达式的算术运算,将代码替换为:
pennyArea = 0.4417860938;
在程序设计语言领域,代码优化占据着重要的地位。许多程序语言极客们将毕生精力倾注于此,他们希望榨干编译器的每一滴性能,将代码优化发挥到极致,使编译器在性能测试中提高哪怕一个百分点,都快成强迫症了。
在本书中,我们将跳过代码优化这一部分的“无底深坑”。令人意外的是,许多成功的程序设计语言在编译时所做的代码优化都很少,它们仅在编译时生成未优化的代码,而将性能优化的重点放到了运行时,如:Lua 和 CPython。
2 . 1 . 6代码生成(Code generation)
当我们对用户程序做完所有能做的代码优化之后,最后一步便是将程序转化为目标平台可执行的二进制机器码,这一步叫做:代码生成(Generating Code、Code Generation、Code Gen)。此处的“代码“指的是可被 CPU 执行的原始汇编机器指令,而不是人类可读的程序“源代码“。
我们终于来到了“后端”,山的右侧部分。从这里开始,程序代码将变得越来越原始,越来越贴近机器所能理解的形式,就像往反方向进化那样。
这时候,我们就需要做个决定了。我们是要生成一枚真正 CPU 的机器指令,还是生成“虚拟” CPU 指令。如果我们选择生成真正 CPU 机器指令,我们将得到一份可执行程序,操作系统可以将这支程序装载到 CPU 芯片上执行。原始机器指令执行起来速度飞快,但是生成目标平台对应的机器指令要费上很大一番功夫。这是因为计算机体系结构发展到现今,已经变得复杂异常:各式各样的机器指令,复杂的指令流水线,还有一大堆足以塞满波音 747 飞机行李箱的历史遗留问题。
如果生成目标芯片的机器码,那意味着编译器会与某个特定体系结构绑定起来。如果编译器生成的是 x86 机器码,那么编译出来的程序无法在 ARM 设备上运行。回到上世纪 60 年代,在那个计算机体系结构、芯片指令集层出不穷的年代,程序缺乏可移植性成了巨大的障碍。
为了规避由计算机体系结构与芯片指令集差异带来的复杂性,马丁·理查德(BCPL 语言设计者),尼克劳斯·维尔特(Pascal 语言设计者)这样的程序语言设计者们都不约而同地选择将程序代码编译到虚拟机器码。他们并没有选择将程序代码编译为某款真实芯片的指令集,取而代之的,将程序编译为某种假想的、理想化的机器码。维尔特将他设计的虚拟机器码称为:p-code,p 表示可移植的(portable)。如今,我们通常称之为字节码(Bytecode),因为每条指令通常占用一个字节的长度。
虚拟字节码指令通常被设计为更加贴近程序语言语义,而不与任何一种计算机体系结构强绑定,这样一来就可以避开体系结构的历史遗留问题了。你可以将字节码想象成是程序语言基本操作的一种紧凑二进制编码形式。
2 . 1 . 7虚拟机(Virtual machine)
如果你选择让你的编译器生成字节码,那么你的工作还没有结束。因为并没有一款真正的计算机芯片可以执行你的字节码,所以你还需要翻译。到了这里,你同样有两种选择,一种是,你可以为每一个目标平台分别编写一支迷你编译器,将你的字节码编译到目标平台的机器码。虽说这样一来你仍需要为每一款需要支持的计算机芯片编写编译器,但字节码编译器的开发工作非常简单,而先前已经实现了的编译流水线则可以在所有支持的机器上被重用。这就相当于,你使用字节码充当了 IR 中间代码。
另一种选择是,你可以编写一枚虚拟机(Virtual Machine、VM),一支在运行时模拟假想计算机芯片,支持字节码指令集的程序。通过虚拟机执行字节码,相比起将字节码编译到目标平台机器码再执行,程序运行效率要慢上很多。这是因为虚拟机要在运行时逐条翻译字节码指令解释执行。作为回报,你收获了编译器实现的简单性与可移植性。你可以使用 C 语言编写一个虚拟机程序,这样一来,你设计的程序语言就可以在所有拥有 C 语言编译器的平台上运行。本书中我们构建的第二枚解释器就是虚拟机工作方式。
2 . 1 . 8运行时(Runtime)
我们终于把用户程序转化为某种可执行形式了,可能是字节码配合虚拟机,也可能是目标平台二进制机器码。最后一步便是运行程序。如果我们编译到目标平台机器码,我们可以简单地招呼操作系统装载可执行程序上 CPU 执行。如果我们编译到字节码,那么我们需要启动虚拟机,加载字节码程序并执行。
不管是哪种情况,对于所有低阶语言(如:汇编语言)以外的程序语言来说,通常都需要在程序运行的时候提供一些额外的服务,例如:如果该语言支持自动内存管理,那我们就需要实现一枚垃圾收集器回收不再使用的内存;如果该语言支持instance of这样的运算符查看对象类型(即:反射),我们就需要在程序运行过程中追踪每一个对象的类型。
所有这些事情都会在程序运行的时候发生,所以被称为运行时(Runtime)。完全编译到二进制机器码的程序设计语言会将语言运行时的代码实现直接插入到编译后的可执行程序之中。Go 语言便是如此,每一个编译后的 Go 程序都被嵌入了一份完整的 Go 运行时拷贝。如果程序在解释器或虚拟机中运行,那么语言运行时就存在于解释器或虚拟机中,大部分虚拟机语言的具体实现都是如此:Java、Python、JavaScript。
2 . 2捷径与可选道路
实现一门程序设计语言真是一条漫长的道路,你需要走过程序编译的每一个阶段。许多程序设计语言完完整整地走过了整条道路,但这其中也有些捷径和可选道路存在。
2 . 2 . 1单遍扫描编译器(Single-pass compilers)
一些简单的编译器将词法解析、代码分析、代码生成这些步骤糅合到一起,直接在解析器中生成目标代码,而不生成任何语法树或其他 IR 中间代码。这些单遍扫描编译器(Single-pass compilers)制约了程序语言的设计与发展。既没有任何中间数据结构存储关于程序的全局信息,也没有办法可以再访问先前已经解析过的代码部分。这就意味着,程序语言必须被设计为,当编译器首次看到程序表达式就能够正确编译的形式。
Pascal 语言与 C 语言就是采用了单遍扫描的设计方式。在 Pascal 与 C 诞生的那个年代,计算机内存极其宝贵,以至于编译器甚至都无法将一份源代码文件完整地载入到内存中,更不用说整支程序了。这就是为什么 Pascal 语法要求类型声明必须出现在程序块开头的位置。这也是为什么 C 语言无法调用代码下方定义的函数,除非做前向声明(forward declaration)显式告诉编译器此处调用函数的必要信息,编译器才能正确地生成出代码。
2 . 2 . 2树遍历解释器(Tree-walk interpreters)
一些程序语言在将代码解析为抽象语法树,再配合上一点静态分析后,就开始执行代码。执行程序的过程,就是解释器从头至尾遍历语法树的分支与叶子节点,对遍历到的每一个节点进行求值。
这样的实现方式在学生项目与小语言中非常普遍,但在通用程序设计语言中并不常用,因为语法树遍历的实现方式运行效率太慢。有些人认为“解释器”一词仅指语法树遍历的实现方式,另一些人则认为“解释器“一词有着更广泛的含义。我会使用明确无争议的树遍历解释器(Tree-walk interpreters) 一词指代语法树遍历的实现方式。我们编写的第一支解释器就采用这种方式。
2 . 2 . 3转译器(Transpilers)
完整编写一门程序设计语言“后端”需要费上很大一番功夫。如果你选择一些已经存在的 IR 中间代码来帮忙实现“后端”,那么你只需要编写一个将程序语言编译到目标 IR 中间代码的“前端”就可以了。不然,你似乎就要被实现“后端”的艰深工作给难住,不知该如何继续了。但是如果,你将其他程序语言当作中间代码呢?
你为你设计的程序语言编写一个“前端”,在语言“后端”部分,不选择完成将程序编译到目标平台机码的所有工作,取而代之的,生成一串语义相同的其他程序语言源代码字符串,这门程序语言和你的程序语言一样同为“高阶”语言。如此一来,你就可以复用那门目标程序语言的编译工具链,编译得到可执行程序了。
这样的编译器通常被称为源到源编译器(Source-to-source Compiler) 或转译器(Transcompiler)。在许多编译到 JavaScript 程序语言(为了在浏览器中运行)大火之后,转译器这个时髦的名字也流行了起来。
虽然第一个转译器被设计用以转译汇编语言,但在目前,大部分转译器都用来将一门高阶语言转译到另一门高阶语言。在 UNIX 操作系统广为流传之后,将程序语言转译到 C 语言逐渐成为了一个传统。每个 UNIX 系统上都有提供 C 语言编译器,另外,C 语言贴近底层,能够生成高效的机器码。所以,把 C 语言作为转译目标语言,可以让你的程序语言在大部分体系结构下都可正常运行。
Web 浏览器在如今也变得越来越流行了,Web 浏览器上的“机器语言”即是 JavaScript。越来越多的程序语言为了能将代码跑在浏览器里,开发了以 JavaScript 为目标转译语言的转译器。
转译器的“前端”部分(词法扫描、语法解析)与其他编译器“前端”相差不多。如果源程序语言只是在目标转译语言之上套了一层语法皮囊,那么静态分析这步就可以忽略,直接生成目标转译语言的对应语法即可。
如果源语言和目标语言的语法相差很大,转译器就可能包含更多的编译阶段,如:静态分析、代码优化等。在代码生成阶段,转译器会生成语义相同的目标语言代码,而不是二进制机器码。
不管哪种方式,接下来,你就可以让转译器生成的目标语言代码走过目标语言已存在的编译流程,拿到最终的可执行程序。
2 . 2 . 4即时编译(Just-in-time compilation)
最后要叙述的这点,并不是一条捷径,而是一座留给程序语言专家攀登的高峰。代码运行效率最高的方式便是将其编译到机器码,但是如果事先并不知道代码最终将跑在哪个目标平台下,该怎么办呢?
你可以效仿 Java 虚拟机 HotSpot JVM,微软公共语言运行时(Microsoft’s Common Language Runtime、CLR),大部分 JavaScript 解释器的做法。当程序在用户机器中被加载时(不管是 JS 代码还是 JVM/CLR 字节码),将代码编译为用户机器体系结构下的二进制机器码。大部分程序语言开发者把这种编译方法叫做:即时编译(Just-in-time compilation),简称 “JIT”(发音类似单词“fit”)。
较为复杂的 JIT 实现中,会在生成的代码里插入性能监测探针,观察哪一块区域的代码是造成性能瓶颈的热点代码,以及都有什么类型的数据流经这些热点代码。观察一段时间后,对这些热点代码应用更高级的优化手段重新编译优化,提高程序运行效率。
2 . 3编译器与解释器
我已经向你的脑袋里塞了一大堆程序设计语言相关的名词术语,现在,我们终于可以引出这个亘古常新困扰程序员们的问题了:编译器与解释器之间的区别是什么?
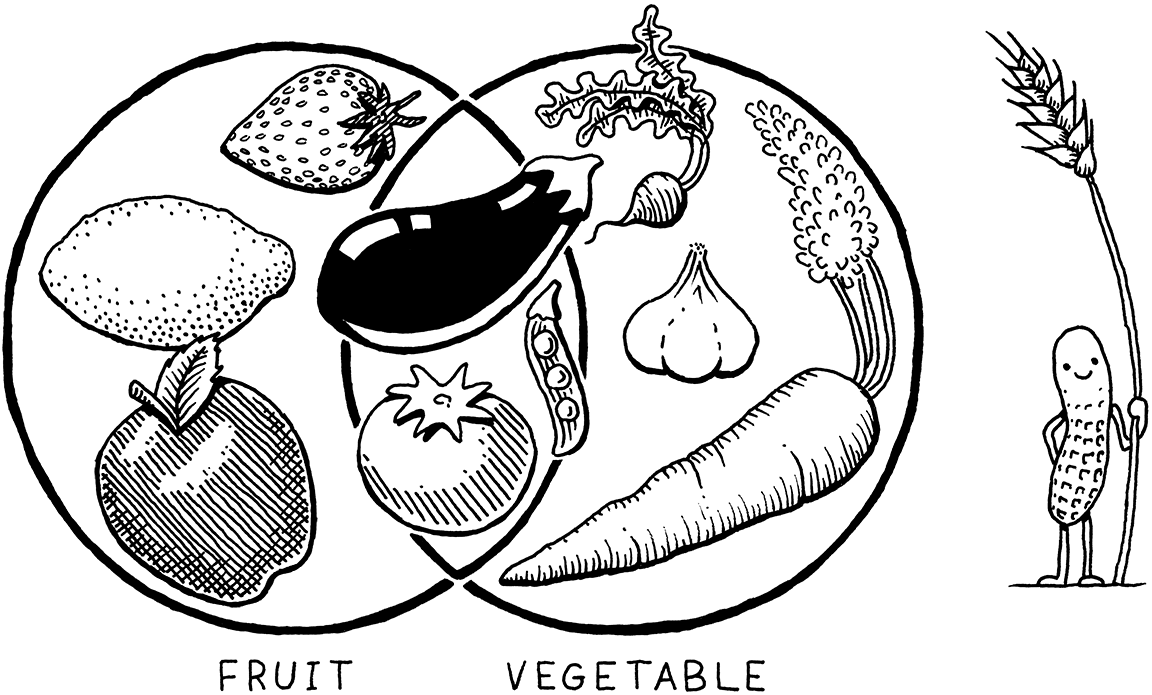
这就像是在问水果与蔬菜之间的区别一样。看起来是个非是即否的二元选择问题,但是实际上,“水果”是个植物学词汇而“蔬菜”是个烹饪用语,这两者之间没有非是即否的二元关系,有的算水果不算是蔬菜(如:苹果),有的算蔬菜不算是水果(如:胡萝卜),但也有的既是水果也是蔬菜(如:西红柿)。
让我们再回到程序语言领域:
- 编译是一种将源语言翻译为其他语言的实现技术。通常会将源语言翻译到更低阶形式,当你从源代码生成字节码或机器码时,你在做编译;当你从源代码生成另一门高级语言时,也是在做编译。
- 如果我们说一门程序语言的实现是一枚编译器,这意味着它是将源代码翻译为另一种形式,而并不执行代码。用户需要自己手动执行编译生成的程序。
- 相对的,如果我们说一门程序语言的实现是一枚解释器,这意味着解释器接收源代码然后立即开始执行。从源代码开始,解释执行程序。
就像苹果和橙子明显是水果而非蔬菜一样,一些程序语言的实现很明显是编译器而非解释器。GCC 和 Clang 将 C 程序源代码编译为二进制机器码。终端用户可以直接运行编译后的可执行程序,甚至不知道该程序是由什么工具编译出来的,所以 GCC 和 Clang 是 C 语言的编译器。
在 Ruby 语言的早期版本实现 MRI 中,用户执行 Ruby 编写的程序,MRI 实现将用户程序源代码解析为抽象语法树,通过语法树遍历的方式执行用户程序。无论在内部还是外部都没有发生任何翻译,所以 MRI 是 Ruby 语言的一枚“解释器”。
对于 CPython 又是什么样的情况呢?当我们运行 Python 程序时,程序源代码被解析转化为一种内部字节码形式,字节码被装载到虚拟机中运行。从用户视角来看,这是解释器,从 Python 源代码直接执行程序而无需编译。但当我们绕开 CPython 表象窥探其内部实现时,我们看到确实有编译行为发生。
所以答案就是:既有编译,又有解释,CPython 同时包含两者。CPython 是一个解释器,解释执行 Python 字节码;CPython 还包含了一个编译器,用以将 Python 程序编译为字节码。在具体实践中,大部分脚本语言都采用这样的实现方式,如图所示:
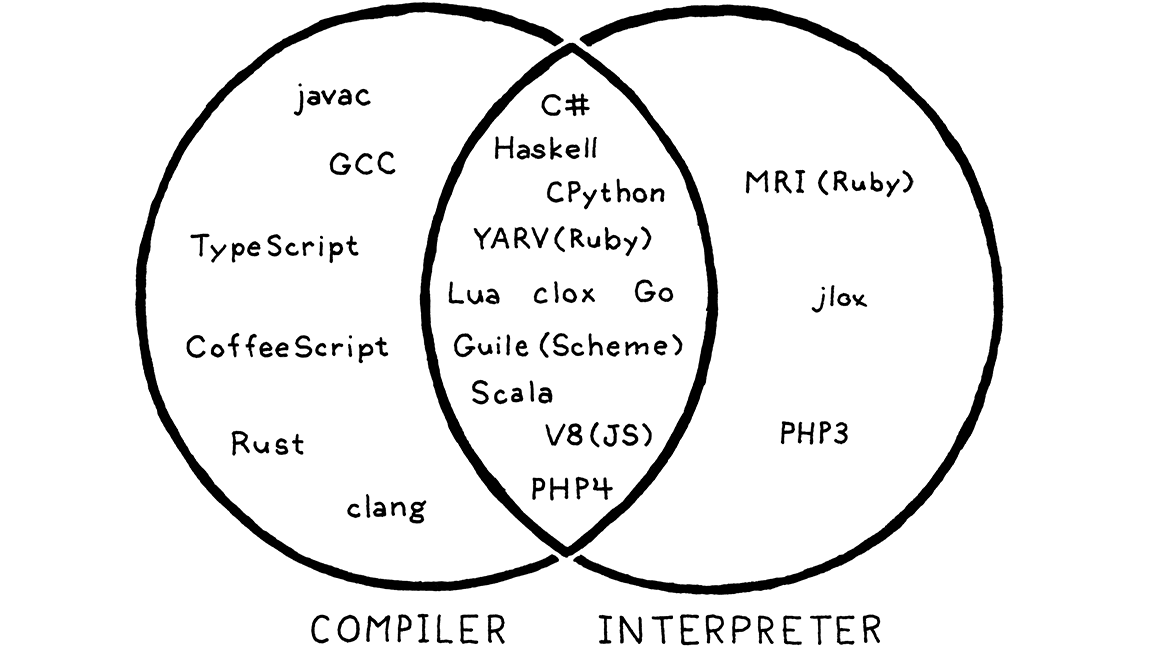
我们的第二枚解释器也将位于图中交集区域。在内部将程序源代码编译为字节码,再通过虚拟机解释执行字节码。本书主要讲解解释器,但也会覆盖到部分编译相关的内容。
2 . 4我们的旅程
在这一章,我们一下子引入了很多的知识与概念,不过无需担心,你不需要短短一章就完全理解这些内容,你只需要对这些内容有个大致的印象,知道内容之间大概是如何串联配合的就足够了。
本章给出的地图会指引你探索本书内容之外更广阔的程序语言世界。我也希望你能突破本书所讲述的内容,探索更广阔的世界。
现在,是时候开始我们的旅程了。系紧你的靴子,背好你的行囊,一起出发吧。从此刻开始,你唯一要做的,就是盯紧你前方的道路。
2 . 5挑战
- 选择一门你喜欢的程序语言的开源实现,下载它的源代码,四处浏览一下,试着在源代码中找到词法分析与语法分析的部分。它们是手写的,还是借助了 Lex 或 Yacc 这样的工具呢(如果发现存在
.l或者.y后缀的文件,那基本就是后者)?
- JIT 即时编译技术应该是运行动态类型程序语言的最快方式,但不是所有动态类型语言都使用了 JIT 技术,它们不使用 JIT 技术的原因有哪些?
- 大部分 Lisp 语言的实现都可以将 Lisp 代码编译到 C ,但是它们同样也会包含一枚可以直接执行 Lisp 代码的解释器,这是为什么呢?